

1.如何更高效地训练出性能卓越的大模型
如何更高效地训练出性能卓越的大模型,始终是人们探索的核心命题。然而,随着神经网络参数量的持续增长,人们逐渐意识到大模型的发展已触及Scaling law瓶颈。大模型性能的提升,需要依赖数据量、参数量以及训练时间的指数级增长,这无疑导致大模型训练成本居高不下,也使得相关研究陷入困境。
多年来,学术界始终未能找到理论层面的突破口,如何将大模型训练从“高成本难题”转化为“低成本可及任务”,成为亟待解决的关键问题。其核心在于,相比于人类在认知层面的学习,端到端训练和评测范式是先天低效的——算法仅注重输出结果与训练数据的匹配度,而无法直接从表征机理层面直接判断并修正神经网络的表征问题。这直接导致训练效率低下,不仅需要海量数据支撑,还对数据清洗的严谨性提出了极高要求。
2.解决大模型关键问题的核心在哪里
在此背景下,我们亟需转换研究视角。解决大模型关键问题的核心,在于【在数学上,能否绕开端到端测试,直接从神经网络表征本身出发,来评估其性能】。
具体而言,当神经网络提取输入语句的特征后,我们能否依据神经网络的表征复杂度或其他属性,直接区分出可泛化、可靠的优质特征与易引发错误的劣质特征?当然,严格地说,对神经网络的表征质量的评估离不开测试样本,但是如果可以大幅降低神经网络模型对大量测试样本的依赖,这无疑将是方法论上的重大突破,大模型的发展或将迈入全新阶段——无需海量测试样本,仅通过分析特征表征,即可量化出神经网络所建模的大部分混乱表征,为大模型研究开辟新的路径。
3.神经网络内部复杂的表征逻辑可以解构为稀疏的符号化交互概念
这里我们需要重点介绍一下,我们取得的两个重要发现和理论证明。
首先,我们证明神经网络内部复杂的表征逻辑,实际上可以解构为稀疏的符号化交互概念。
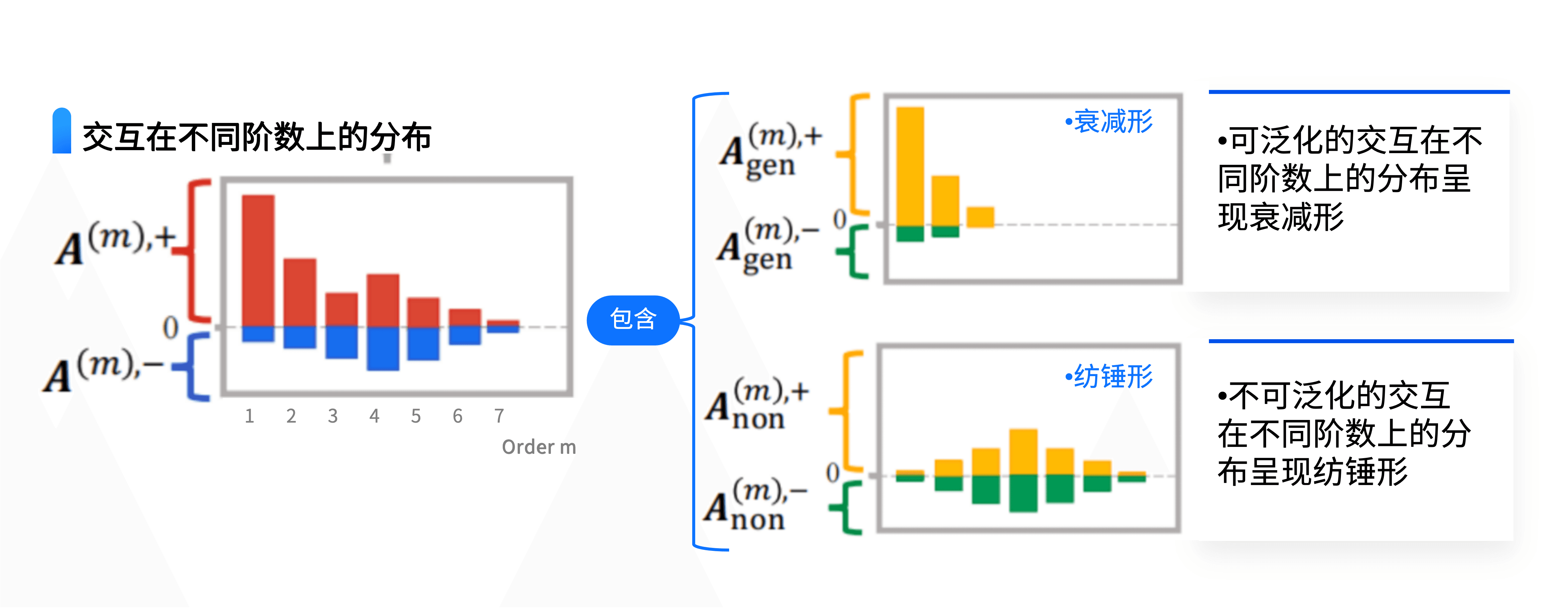
以大语言模型例,其自动建模了不同单词或词组间交互关系,每一个交互可以视为神经网络所自动建模的词组概念,并会对目标单词的输出置信度产生特定的数值影响。我们证明神经网络在一个输入样本上所建模的交互的数量是有明确的上界的,基于约100-150个左右的关键交互,往往就能严谨且完整地呈现神经网络在处理特定句子时,其内部发生的所有复杂变换。这一成果不仅实现了理论层面的重大突破,更从机器表征层面确保了解释的严谨性与精确性。
4.神经网络所建模的交互作用
其次,我们进一步研究发现,神经网络所建模的交互作用可分为两类:
⭐️ 一类是能够有效泛化到测试样本的可泛化交互;
⭐️ 另一类则是无法在测试样本中适用的不可泛化交互。
尤为关键的是,我们揭示了这两类交互各自独特的分布规律。可泛化交互多集中于低阶,且随着交互复杂度的提升,其交互作用强度呈递减趋势。而不可泛化交互呈现出两大显著特征:其一,在数值上常表现为交互效应相互正负抵消;其二,在复杂度分布上呈纺锤形——中等复杂度的不可泛化交互数量最多,而过于简单或极其复杂的不可泛化交互较少。凭借这些发现,我们得以从表征层面量化神经网络中可泛化与不可泛化交互的分布,进而直接度量神经网络的过拟合程度,为神经网络的优化与改进提供全新的分析视角和量化依据。


