

1. How to Train High-Performance Large Models More Efficiently
The efficient training of high-performance large models remains a key area of exploration. However, as the number of neural network parameters continues to increase, it has become evident that the development of large models has reached the bottleneck of Scaling Laws. Enhancing the performance of large models demands exponential growth in data volume, parameter count, and training time, which, unsurprisingly, keeps the training costs high and research increasingly challenging.
For years, the academic community has struggled to identify a theoretical breakthrough. The critical issue is transforming large model training from a 'high-cost dilemma' into a 'cost-effective attainable task'. The heart of the problem lies in the fact that, unlike human cognitive learning, end-to-end training and evaluation paradigms are inherently inefficient. Algorithms focus solely on the alignment of output results with training data, failing to directly interpret and correct representation issues within neural networks. This inefficiency necessitates vast data support and stringent data cleansing requirements.
2. The Core to Solving Key Issues in Large Models
In this context, we urgently need to shift our research perspective. The core of solving key issues in large models lies in determining [whether performance can be evaluated directly from neural network representations, bypassing end-to-end testing].
Specifically, after a neural network extracts features from input statements, can we directly distinguish high-quality, generalizable, reliable features from poor-quality, error-prone ones based on the network's representational complexity or other attributes? Strictly speaking, the evaluation of network representation quality relies on test samples, but if we can significantly reduce the model's dependence on a large volume of test samples, it would undoubtedly be a significant methodological breakthrough. The advancement of large models could enter a new phase—quantifying disorderly representations modeled by neural networks through feature representation analysis alone, without massive test samples, paving a new path for large model research.
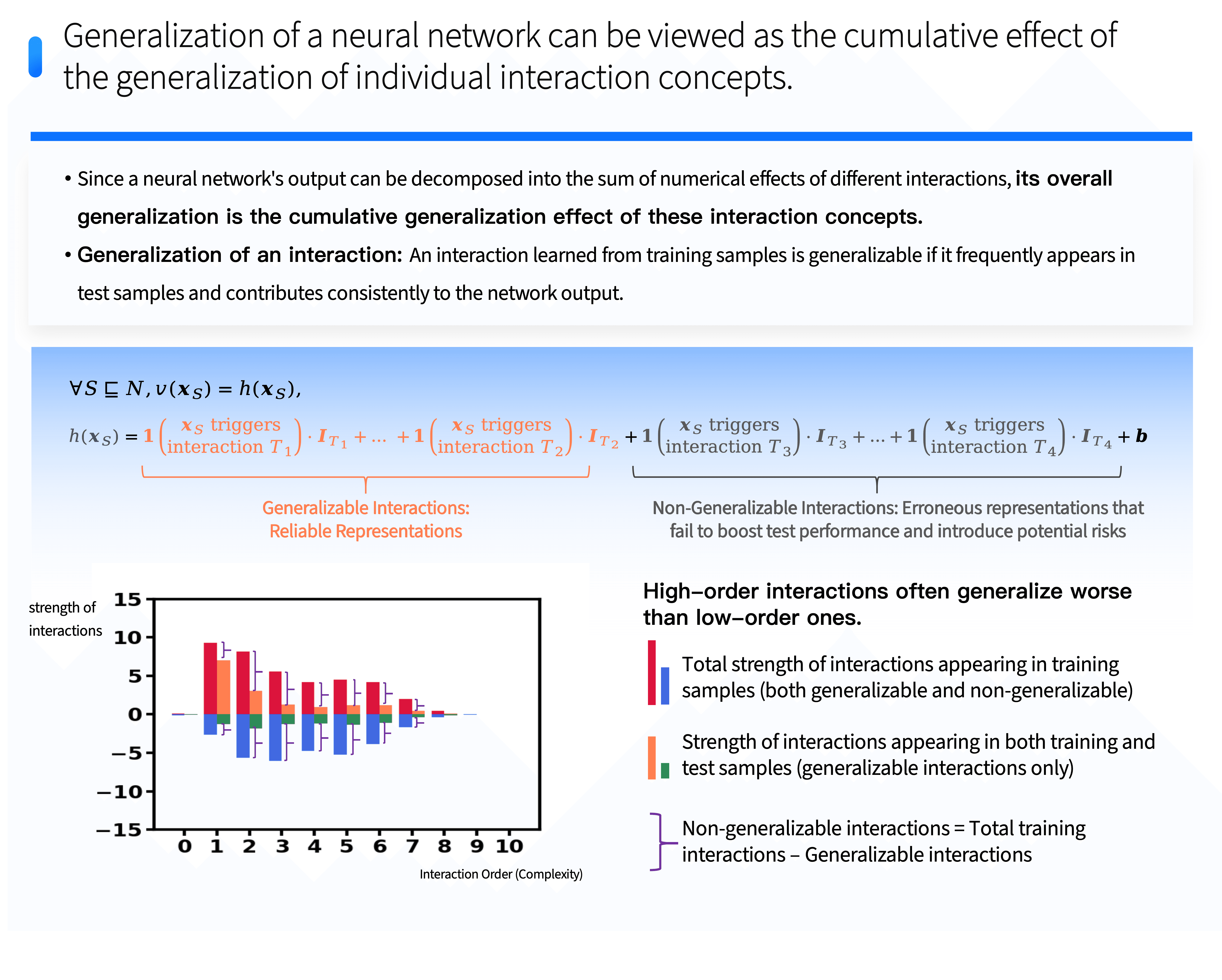
3. The Complex Representational Logic within Neural Networks Can Be Deconstructed into Sparse Symbolic Interaction Concepts
Here, we emphasize two important discoveries and theoretical proofs we have achieved.
First, we proved that the complex representational logic within neural networks can indeed be deconstructed into sparse symbolic interaction concepts.
Taking large language models as an example, they automatically model interaction relationships between different words or phrases, where each interaction can be viewed as a phrase concept automatically modeled by the network and exerts a specific numerical influence on the output confidence of the target word. We demonstrated that the number of interactions a network models upon an input sample has a clear upper limit. Typically, around 100 to 150 key interactions suffice to rigorously and comprehensively represent all internal complex transformations occurring when a network processes specific sentences. This result achieves a significant theoretical breakthrough while ensuring the rigor and accuracy of explanations from the machine representation level.
4. Interactions Modeled by Neural Networks
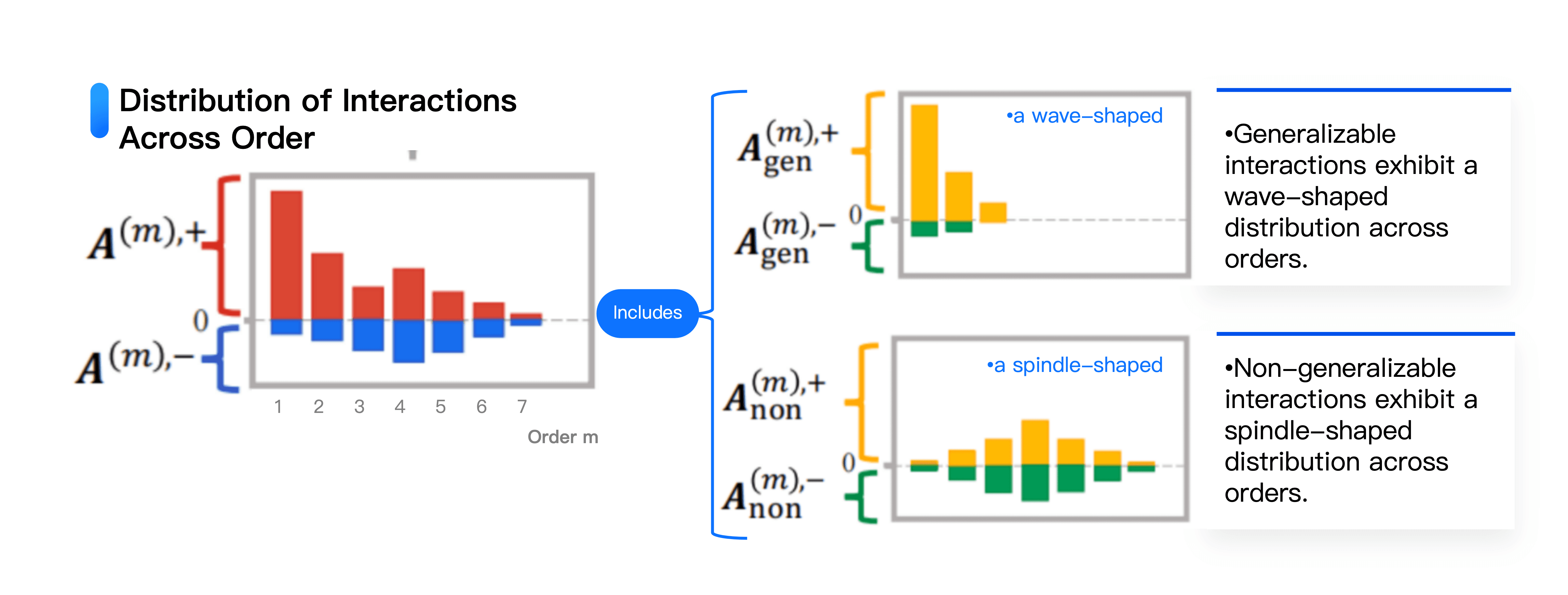
Secondly, our further research discovered that interactions modeled by neural networks are categorized into two types:
⭐️ One type effectively generalizes to test samples—generalizable interactions;
⭐️ The other type is non-generalizable interactions, which do not apply to test samples.
Crucially, we unveiled the unique distribution patterns of these two types of interactions. Generalizable interactions tend to concentrate at lower levels, and their interaction strength decreases as complexity increases. Non-generalizable interactions exhibit two prominent features: numerically, their effects often cancel each other out; in terms of complexity distribution, they form a spindle shape—medium complexity interactions are most numerous, while both overly simple and extremely complex non-generalizable interactions are rare. These findings enable us to quantify the distribution of generalizable and non-generalizable interactions on the representational level, directly measuring a network's degree of overfitting. This provides a novel analytical perspective and quantitative foundation for neural network optimization and enhancement.


