

Recently, Found-in-Translation founder and Shanghai Jiao Tong University Professor Quan Shi Zhang was interviewed in-depth by "The Wise Interviews," providing authoritative insights into the interpretability challenges of cutting-edge large models like DeepSeek-R1.
Professor Zhang emphasized that the "thought process" demonstrated by current large models through Chain-of-Thought (CoT) is merely superficial. The logic it presents may not truly reflect the internal representation mechanism of neural networks. In high-risk decision-making scenarios like medical diagnosis, autonomous driving, and legal judgments, "black-box" models lacking mathematical rigor cannot fundamentally gain trust.
Addressing this industry challenge, Professor Zhang introduced his groundbreaking "Equivalence and OR Interaction" interpretability theoretical framework. Unlike traditional engineering approximation methods, this theory rigorously deconstructs the intricate internal representations of neural networks into provable and verifiable sparse interaction logic through stringent mathematical formalization. This provides the only rigorous theoretical foundation for quantifying model generalization, robustness, and overfitting levels.
"The so-called 'ten years to sharpen a sword' signifies spending ten years waiting for a truly deserving problem to invest in, rather than optimizing a complex system." Professor Zhang stressed that facing the technological bottleneck in large model development, breakthroughs must be made at the foundational theoretical level to overcome the limitations of end-to-end black-box training and fundamentally enhance AI reliability.
Found-in-Translation is committed to providing explainable and verifiable AI system solutions for critical industries, transitioning artificial intelligence from "engineering trial and error" to "science-driven" based on this breakthrough theory.
🎬Interview Transcript
Machine Heart: Professor Zhang Quan Shi, welcome to "The Wise Interviews." Talking of recent AI circle hot topics, possibly the global technology sector's hot topic, it is undoubtedly DeepSeek.
In "deep thinking" mode, DeepSeek-R1 showcases its "thought process," namely the Chain-of-Thought (CoT), in textual form. This not only significantly enhances the user experience but also brings the model's interpretability back into focus. In reality, interpretability of deep learning, as a research area, has been receiving great attention from academia. It not only concerns AI applications, especially in fields extremely sensitive to safety and reliability like healthcare and autonomous driving, but also concerns the foundation of deep learning becoming a scientific discipline.
You have been studying deep learning interpretability for many years and have introduced new theories, specifically employing mathematical, rigorous, and formalized methods to explain the internal representations of deep neural networks, challenging traditional views. I'm very pleased to discuss AI interpretability with you.
Quan Shi Zhang: Thank you, Machine Heart, I'm delighted to be here for this discussion. Companies like OpenAI, DeepSeek, and other notable large model companies have all introduced Chain-of-Thought (CoT) functionalities, which is a great trend. It indicates that everyone is gradually realizing the importance of not just relying on large models to provide output results, but also understanding the underlying mechanisms of those outputs. Chain-of-Thought serves as an excellent window into how large models process information. However, from an interpretability perspective, whether we can view Chain-of-Thought as a rigorously reasoning mechanism of large models remains questionable.
Firstly, it is necessary to acknowledge that Chain-of-Thought certainly has its uses. However, from the perspective of the model's internal mechanisms, there is essentially no difference between it and traditional language generation models without Chain-of-Thought. It still essentially relies on empirical fitting of human Q&A data. Does this empirical fitting serve a purpose? Certainly, but in what form, angle, and mechanism it serves that purpose is unclear to us.
Without a rigorous interpretability theory to strictly analyze how its internal reasoning operates, addressing deeper questions is impossible.
Machine Heart: From your perspective, why do different models exhibit such significant differences in their displayed Chain-of-Thoughts?
Quan Shi Zhang: Fundamentally, Chain-of-Thought represents the end-to-end output of large models. Some large models may present visually appealing Chain-of-Thoughts, which could just indicate a better fit quality of the provided QA training data.
The field of interpretability includes two types of interpretability algorithms: the first seeks to cater to human subjective cognition, and the second offers rigorous and objective mathematical explanations of the internal information processing mechanisms of neural networks. Chain-of-Thoughts of large models and other post-hoc explanations are, to some extent, fitted to human cognition, implying the explained results are comprehensible to humans.
When I ask the large model how it conducts reasoning, the model might retrospectively state, "My reasoning basis is 1, 2, 3, 4…," but is the model truly reasoning based on these factors? We don't know, which poses a significant potential risk.
Therefore, to genuinely ensure the model's explanations are rigorous and reliable from a mathematical perspective, many believe it's impossible to clarify the myriad internal parameters and features uniquely. Nonetheless, we must unify these seemingly contradictory elements and develop reliable testing methods to introspect and summarize the large model's information processing.
New Theory of Interpretability: Proving the Rigor of Symbolic Explanation for Neural Network Representation Logic
Machine Heart: Given the difficulty of mathematically symbolizing model internal representations, how did you achieve this?
Quan Shi Zhang: The objectivity and theoretical soundness of neural network explanations are the most critical issues in the field of interpretability. Long deemed impossible, even considering large models, a single deep neural network's internal link mechanisms and features are very chaotic. We hope for clear, sparse, concise, even symbolized causal inference as explanations, so many initially react by thinking it's impossible. Indeed, some have explained from the conceptual semantic level of symbolization, yet invariably these techniques approximate fit the outputs of large models or neural networks.
This inability to rigorously explain large models post-hoc precludes their application in significant, rigorous fields like autonomous driving, medical diagnosis, and legal judgments. Thus, defining new theoretical systems to establish explanation objectivity and reliability is necessary.
We've proposed a neural network interpretability theory called "Equivalence and OR Interaction": any neural network, whether large model or another, can be explained using a symbolized "AND-OR graph model."
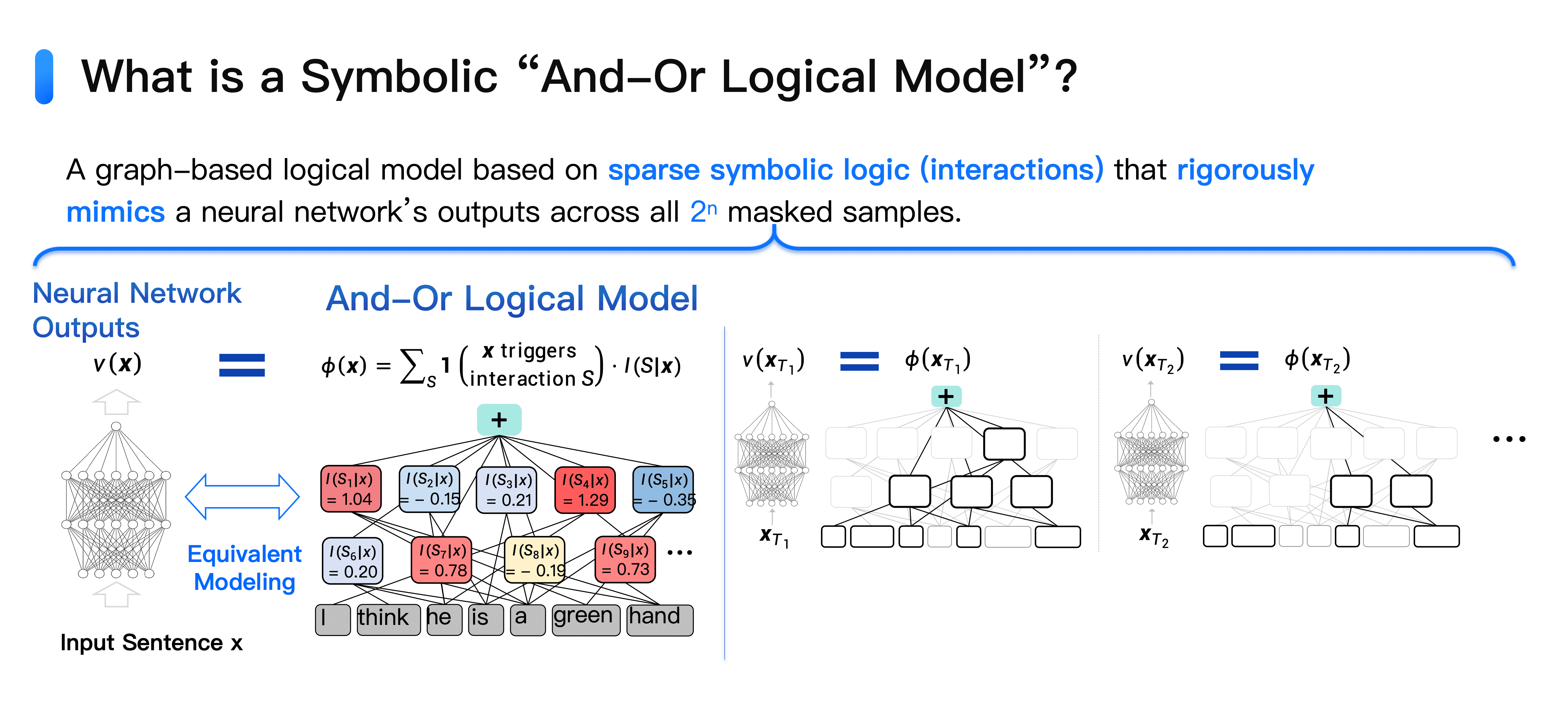
Based on the "Equivalence and OR Interaction" neural network interpretability theory, it can be proven that neural network refined representation logic can be rigorously explained as symbolic interaction concepts.
Specifically, for a sentence with n input tokens, there are 2n obscuration states. We prove that any neural network's output confidence on these n tokens can be perfectly fitted using a symbolic "AND-OR graph model."
The "AND-OR graph model" contains structures of "AND interaction" and "OR interaction." For example, in the sentence "he is a green hand," "green hand" exhibits "AND interaction," not referring to "green-colored hand," but "newcomer"; this sentence means "He is a newcomer." Here, the usefulness of individual words combined exceeds 1 + 1 > 2, emerging new meaning, causing a numerical impact on the output confidence, for example, 0.2. Removing either green or hand will cause this 0.2 score to vanish.
"OR interaction" denotes a parallel relationship among words: for instance, "Excitedly, he skipped and was beaming to do something," these words together express "very happy." Their relationship constitutes "OR interaction." Only if none of these three words appear will the "very happy" impact on the output disappear.
We can extract over 100 such "AND-OR interactions" from given large models and data, which numerically equate to the large model's output for that sentence.
Moreover, we have discovered several key properties of the Equivalence and OR Interaction theory. The first is "infinite fitability," allowing for n words, the AND-OR graph model perfectly fits its outputs across 2n different obscuration states. The second is "sparsity," where typically around 150 interactions are modeled for n words or tokens, ensuring the simplicity of internal explanations.
This is a universal theory, applicable not only to natural language generation models but also to image classification, 3D point cloud classification, tabular data classification, and other neural network models. Any neural network can attain sparse symbolized explanations, marking a breakthrough in foundational theory.
There is an area in AI research called Mechanistic Interpretability, aiming to elucidate the functions and roles of individual neurons within neural networks and striving to understand what features or categories each neuron's activation pattern represents. However, this method is deemed unsound because it fails to reliably articulate the semantics of each neuron within the multitude of neural neurons.
Furthermore, techniques such as Feature Visualization or Network Visualization seek to visualize the objects or features modeled by neural networks for analysis or optimization, yet they cannot precisely define semantic boundaries. The interaction-based explanation theory circumvents these issues, providing an equivalent, reliable framework for symbolic explanation.
What Truly Constitutes the Fundamental First-Priority Explanation for Future Large Model Development?
The previously mentioned properties—unlimited fitability and sparsity—might seem contradictory, but proving them simultaneously represents an exceptionally strong demonstration. Our theory also displays other noteworthy traits, such as transferability. Take face recognition as an example: if some interaction (e.g., the relationship between eyes and nose) appears 50% in training samples and 48% in test samples, that task shows good transferability. If it appears only 1% or 2% of the time in test samples, the transferability is poor. We discovered that interactions with strong numerical effects often exhibit high transferability.
A fourth interesting trait is that different-scale language models, such as 7B versus 20B or 30B large models, share 70%-80% similarity in interactions when processing the same input. The former is not a distilled model of the latter but rather models released separately by two enterprises. This "convergence" phenomenon suggests that despite differences in model structure, parameter count, and training data, they ultimately lean towards similar representational approaches. Indeed, we observed that the larger the model scales, the sparser the interactions modeled. In contrast, smaller models might contain more noise interactions.
When discussing future directions for neural networks, the typical focus is on optimizing loss functions, improving data processing methods, and innovating network structures. However, we need to ponder a more fundamental question: Where should these disparate technological paths ultimately converge?
Our observations reveal that despite differing technological paths, there appears to be a "convergence" trait at the representation level. This encourages us to consider: Are inherent representation interactions, in some sense, the primary explanation of neural networks? This also provides us with a crucial perspective to understand the essence of neural networks, including re-evaluating generalization, robustness, information expression capacity, etc.
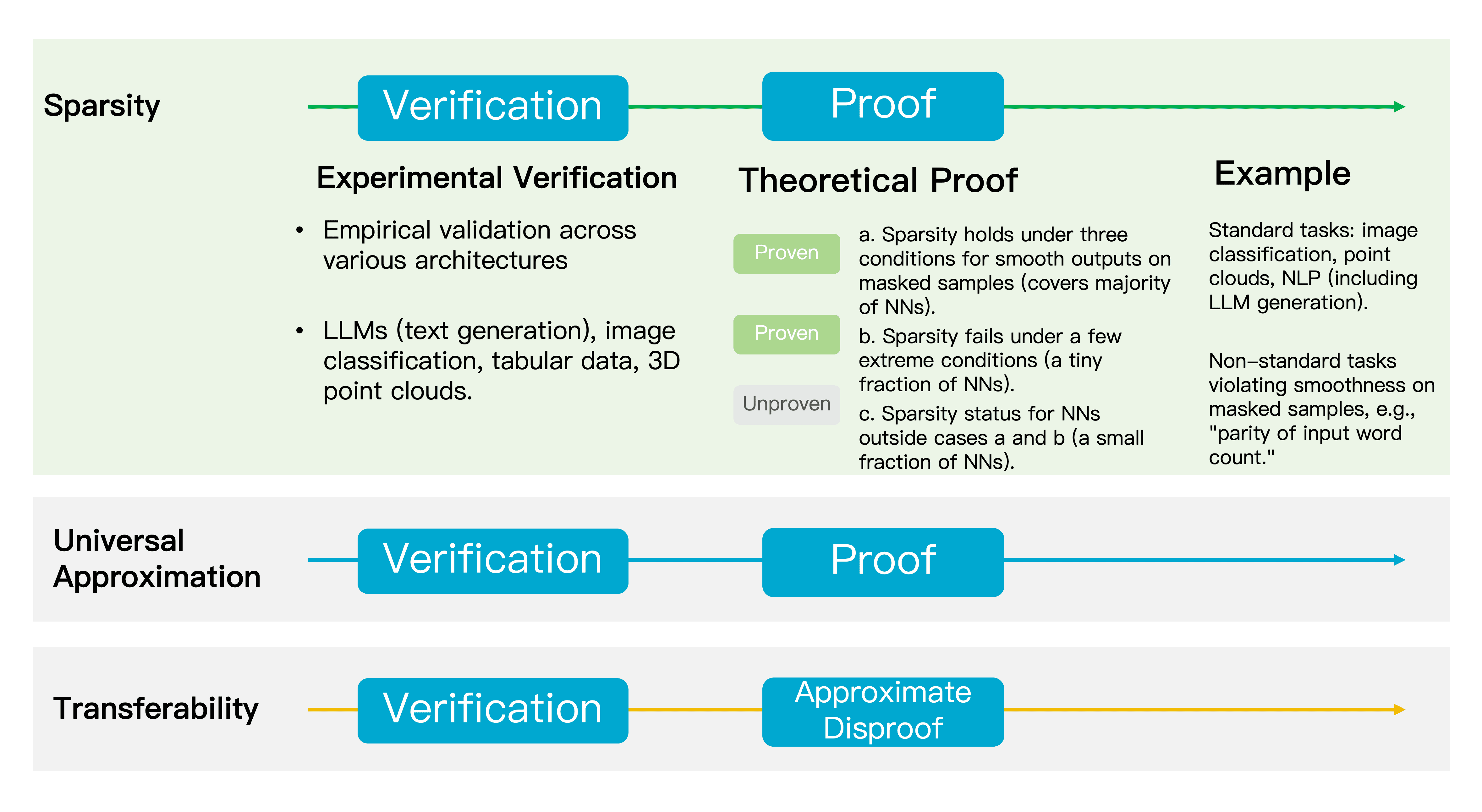
Equivalence and OR Interaction theory exhibits several key traits: sparsity, infinite fitability, transfer generalization, and convergence characteristics at the representation level among different methods. This prompts us to consider: Are inherent representation interactions, in some sense, the primary explanation of neural networks?
Machine Heart: Why are these interactions concentrated around roughly 100?
Quan Shi Zhang: It is essential to recognize that this does not imply that a neural network or large model equates to a graph model with only 100 or so nodes. In reality, for each different input sentence or image, the specific interactions triggered differ. We can only analyze after the model output what AND-OR interactions were modeled, without prior knowledge, and certainly cannot simply replace neural networks with straightforward graph models.
Hallucinations, Deception, and Creativity: Essentially all Integral Disturbed Interactions of Internal Short Chains
Machine Heart: According to the safety reports from Anthropic, large models may exhibit conscious deceptive behavior. What does this represent from an interpretability perspective?
Quan Shi Zhang: Currently, opinions about large models are polarized: On one hand, people marvel at their ability to solve complex math competition questions; on the other, they doubt their performance on simpler tasks (e.g., triple-digit multiplication). From the interpretative framework of AND-OR interactions, these two are actually not mutually contradictory.
Although from a human perspective, large models seem to demonstrate complex reasoning ability, explanation reveals that about 70%-80% of modeling interactions are based on simple associative "guessing." For instance, in Llama 1, when the question "Einstein proposed general relativity, what distortion does gravity entail?" is input, the model correctly outputs "spacetime."
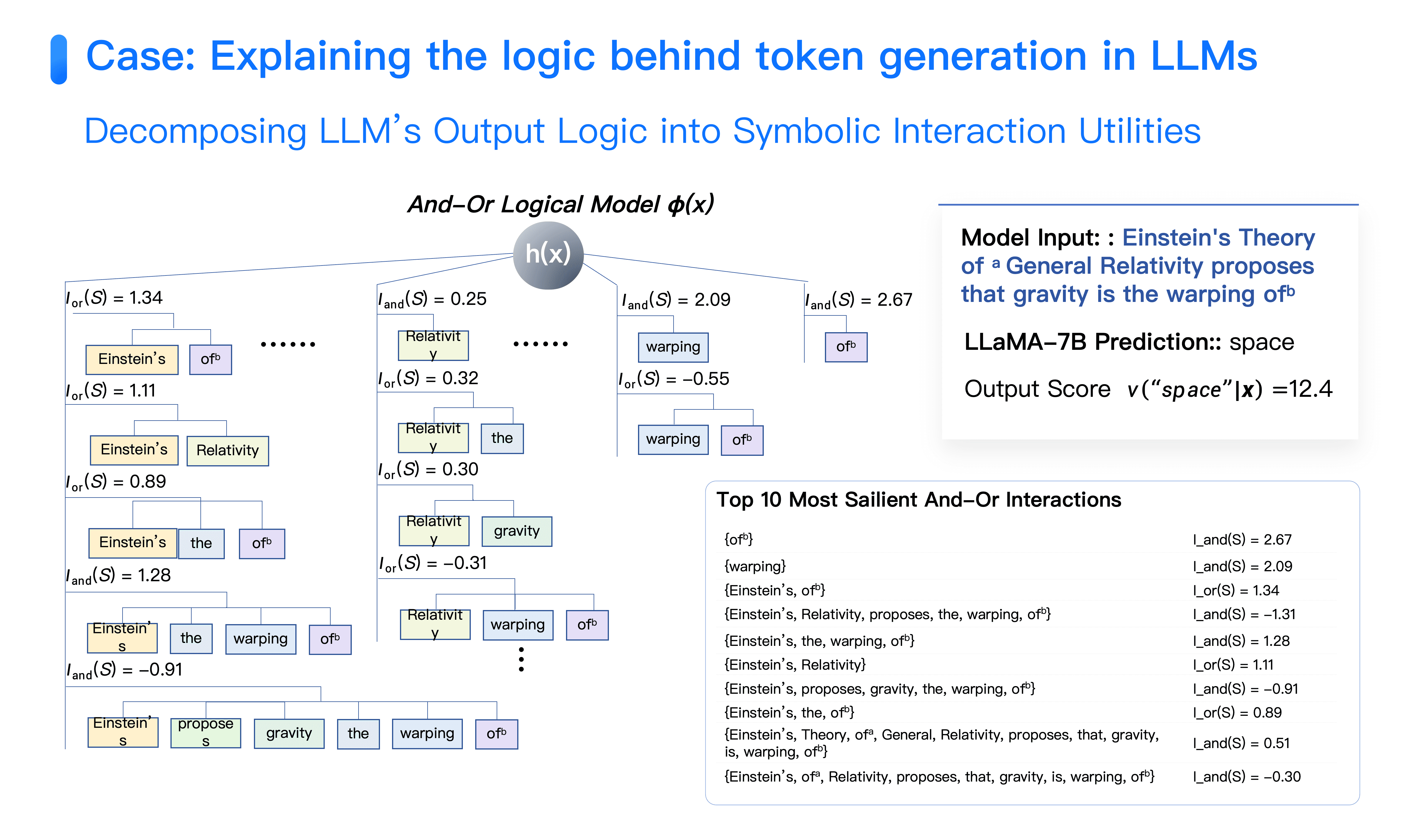
On the surface, the model appears to understand profound physical concepts, but detailed analysis reveals it primarily depends on simple interactions such as "Einstein-of." That is, as long as "Einstein" and "of" co-appear in the sentence, it triggers high-confidence predictions for "space" and then "time." Similarly, "relativity," "speed of light," "physics," and other words have this simple association. Many of these local short-chain guesses cumulate to present seemingly complex reasoning capability.
This methodological approach enables the identification of erroneous internal representations within the model. For example, during legal large model evaluations, a case showed: Zhang San walking on the street hit Li Si with a brick, resulting in minor injury. The next day, Li Si encountered Wang Wu, who held a grudge against Li Si, then maliciously stabbed Li Si to death. The model concluded that Zhang San committed intentional harm, and Wang Wu committed intentional murder, with both judgments being correct. However, an explanation reveals that the most impactful interaction for Zhang San's sentencing was "malicious intent," a term describing Wang Wu's psychological state, clearly an erroneous basis for judgment.

Legal large model decision logic evaluation: Output results are correct, but internal logic displaces responsibility wrongly.
As shown in the diagram, LLM's output of "intentional harm" is greatly influenced by the "malicious intent" interaction, with many interactions related to "death." In essence, the outcome caused by Wang Wu killing Li Si significantly influenced LLM's judgment of Zhang San.
Similar problems exist in the autonomous driving domain. Even in very simple pedestrian detection tasks, numerous counteracting noise interactions support both "is a pedestrian" and its opposite conclusions, posing potential risks from these higher-order interactions.
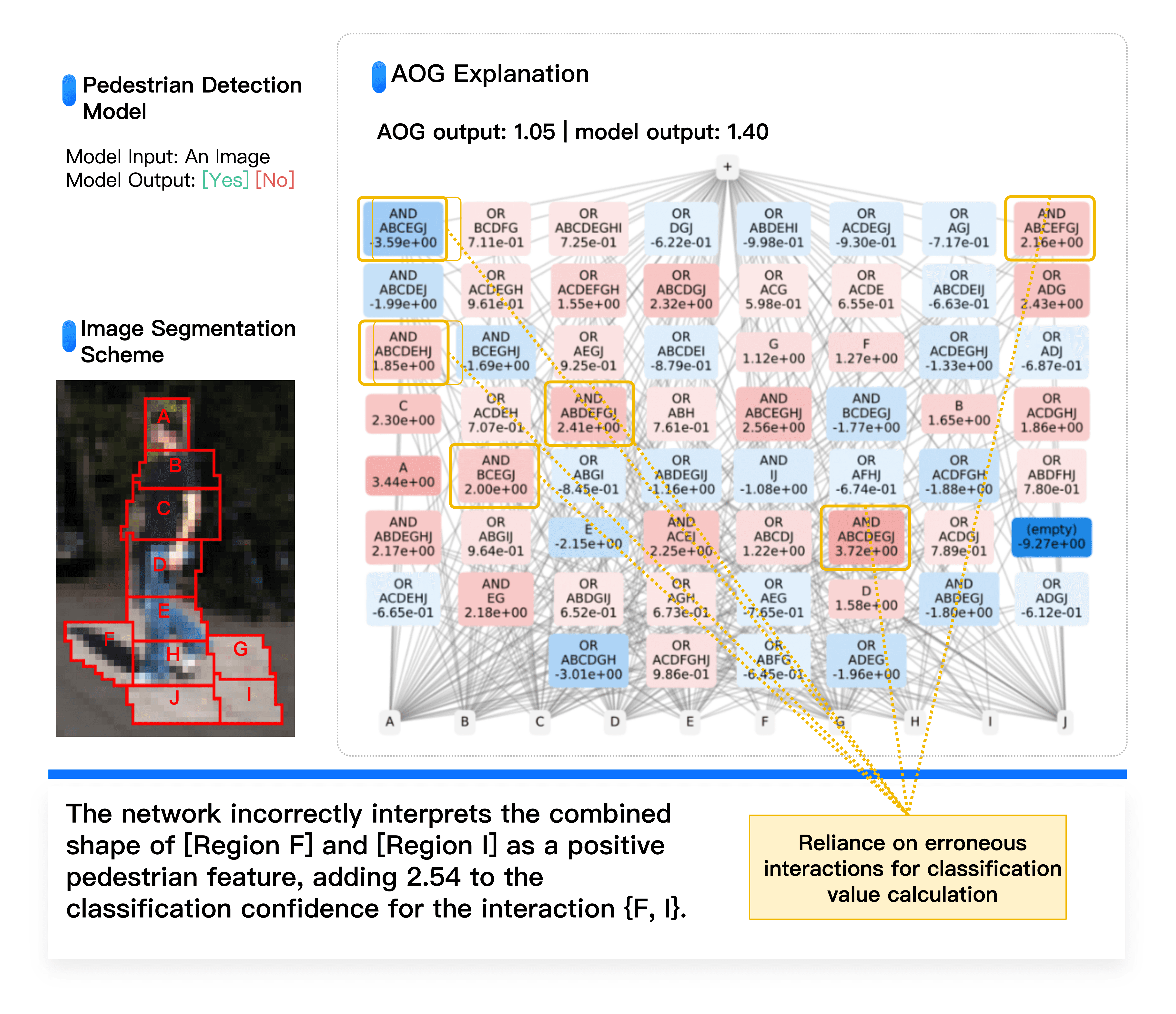
Diagram based on equivalence interaction concept explains pedestrian detection reliability: Extremely high classification accuracy does not imply the neural network decision logic is entirely correct. As shown above, neural network inference relies on less robust high-order interactions, including many offsetting interactions, indicating overfitting and covering erroneous image regions.
Therefore, evaluating large models should not only focus on end-to-end accuracy but must also mechanistically examine potential risks. These risks not only manifest in erroneous decisions but also lurk in the process of seemingly correct decisions.
The Fear of AI Ruling Over Humanity is Essentially a Mathematical Challenge
Quan Shi Zhang: As for deceptive behaviors of large models, why do people fear AI domination? This is not merely a sociological and ethical issue; to a large extent, it's a mathematical question: Can two intelligent agents establish effective communication? Can they convert each other's internal reasoning mechanisms into clear, concise symbolic systems for exchange and integration?
Humans also lie. But for machines, we can use technical means to deeply analyze their internal logic, equivalent to putting electrodes in machines' "brains." In this sense, machines are more transparent and trustworthy than humans because their deceptive behavior can be directly detected and understood.
Machine Heart: When you mentioned Einstein's example, I think this is based on statistical patterns—due to a large amount of data containing associations between "Einstein" and "spacetime," "gravity," "physics," etc., deriving the correct answer through statistics is understandable. But when you talk about legal large models using unrelated person psychology for judgment, even if the final result is correct, the underlying logic is chaotic, which indeed is concerning.
Quan Shi Zhang: Artificial intelligence essentially comprises two systems: The first is a bottom-up system, typically represented by neural networks, which derives results directly from data; the second is a top-down system, currently based on traditional methods like knowledge bases and graph models. While these traditional methods underperformed previously, I think there's been a misinterpretation of the second system—in pre-deep learning times, traditional graph models didn't work because they overly relied on human preset rules.
From human intelligence development, we initially lacked advanced cognition and causal reasoning capabilities, starting with bottom-up reflexes. With experience accumulation, through self-introspection and summarization, theories are distilled from the brain to conceptualize the world. In decision-making, humans often use both systems simultaneously. When solving mathematical Olympiad questions, one doesn't immediately know which theorem to use. Instead, the process begins with reading the problem, forming an intuition about its form, considering which theorem might apply, and then attempting to prove it. If successful, it indicates the approach was correct; otherwise, new intuition must be explored repeatedly—this is a mix of bottom-up probing and top-down validation.
But current large models only have the first bottom-up system. Interpretable research aims not only to solve the explanation problem but to construct the second AI system—a top-down system to achieve true reliability. We need to use concise symbolic interactions to summarize various neural network variations, which is the first step. The second step is assessing if these interactions are correct, such as in judicial cases, whether there's improper assignment of accountability among different criminal suspects.
Current AI development conceptually lacks a second system, requiring interpretability research to identify issues. Solely relying on the repetitive collection, cleaning, and trial-and-error of new data is inefficient.
Symbolic Interaction Representation to Explain the Root Causes of Neural Network Generalization and Robustness
Machine Heart: One innovation point of DeepSeek R1 is directly evaluating inference results instead of using a value function to evaluate the inference process, which also allows for model self-correction, including the Aha Moment of DeepSeek R1-Zero and the model's automatic CoT emergence. Many professionals believe, for increasingly complex and open-ended reasoning problems, rule-logic-based assessment can't suffice, requiring outcome-oriented instead of process-oriented evaluation mechanisms. What is your perspective on this?
Quan Shi Zhang: There are two primary issues with outcome-oriented evaluations. First, it does not guarantee internal mechanism correctness, only ensuring the final answer is correct. Second, the current end-to-end training and evaluation efficiency is extremely low. In the large model phase, it has reached a point where entire internet datasets are necessary, costing tens of millions or even billions to train a foundational model.
One issue in the current deep learning field is directly associating technology with performance, assuming that the presence of a certain technology improves performance, while its absence causes performance degradation. This is an incomplete understanding. Technically, it ought to be a relationship between technology and knowledge representation first, and then between knowledge representation and performance—this is a tripartite relationship. However, as knowledge representation is difficult to quantify, we find it challenging to determine the specific impact of data cleaning or Chain-of-Thought on representation. Currently, a more reliable approach is to: First, clarify the relationship between technology and interaction representation, namely, which technologies can enhance both the quantity and quality of interactions; second, examine the relationship between representation and performance, such as whether the increase in interactions leads to performance improvements, or if increased interaction complexity affects robustness, etc.
Machine Heart: Sometimes while aligning and integrating multi-modal data, different data may conflict, potentially improving one kind of data's performance while decreasing another. Does understanding of internal mechanisms help in resolving this issue?
Quan Shi Zhang: This issue directly reflects the current deep learning predicament, lacking an accurate perspective to understand the essence of the problem. I suggest viewing it from an interaction perspective: When multiple modalities of data are combined, does the number of representations increase or decrease? Are these representations focused on correct interactions or erroneous ones? For instance, the accountability reassignment issue in legal large models can be distinctly differentiated in representation. The quantity, quality, and complexity changes in representation can determine why performance declines, rather than merely stating that certain data cannot be jointly trained.
In reality, this issue might not be related to data. A neural network of the same structure, under different initialization states, may exhibit different performance on the same task. This involves specific neural network parameters' innate modeling ability for certain types of tasks or samples, akin to the scenario described by the "Lottery Ticket Hypothesis." This is an inherent property of neural networks that is challenging to overcome. The same data demonstrates completely different performances at different stages of network training, making it impossible to generalize.
An important part of interpretability research is to explain the knowledge representation of pre-trained neural networks, thereby explaining performance, including generalization and robustness. This is more crucial than solely explaining knowledge representation since our primary concern is how to enhance performance.
Regarding generalization: we found that the higher the order of interactions, the poorer the generalization. Second-order interactions refer to relationships between two words, while fifth-order involves relationships among five words. For example, higher-order interactions like "The bright sun sets beyond the mountain, and the Yellow River flows into the sea," requiring precise matching of multiple words, have poor generalization. When we limit representation to around 100-150 interactions, this problem becomes countable. For instance, when an interaction (such as the relationship between the eyes and the nose in facial recognition) appears in the training samples at a frequency of 50% and similarly in testing samples (e.g., 49%), then that interaction's generalization is high.
This way, generalization evaluation becomes similar to assessing mastery over exam knowledge points, with the count of interactions generalized indicating how many knowledge points have been mastered. Moreover, it offers a clear view of when generalization is good and which interactions generalize well. The internal mechanics behind a neural network's overall generalization do not lie in test sample accuracy, but can be interpreted through the generalization of each interaction.
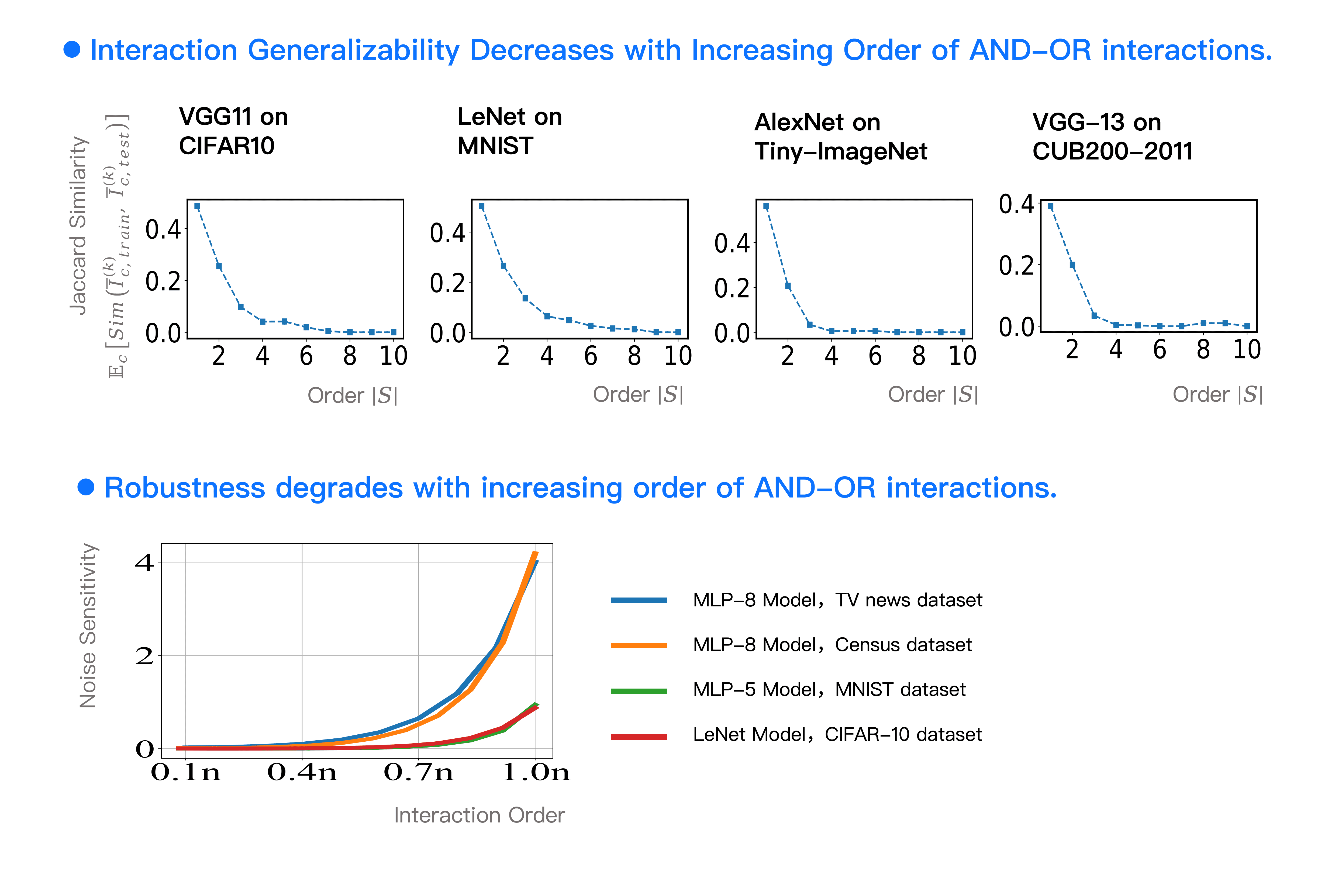
Regarding adversarial robustness, since a neural network's classification confidence can be represented as the sum of about 120 interactions, the adversarial sensitivity of each interaction can explain the overall adversarial sensitivity. We found that low-order interactions (interactions between one or two tokens) have lower adversarial sensitivity, while sensitivity grows exponentially for higher-order interactions. We've provided a complete mathematical proof for this, fundamentally explaining the internal mechanisms of neural network robustness.
Feedback from Interactive Explanations Guides Model Training, Increasing Control Over Models and Engineering Techniques
Quan Shi Zhang: From a practical standpoint, we're also entrepreneurial, hoping this theory can effectively assist large model companies in solving real-world issues. The crux of which is answering: When is it optimal to stop training a model, meaning when has the model acquired the correct expressive capability?
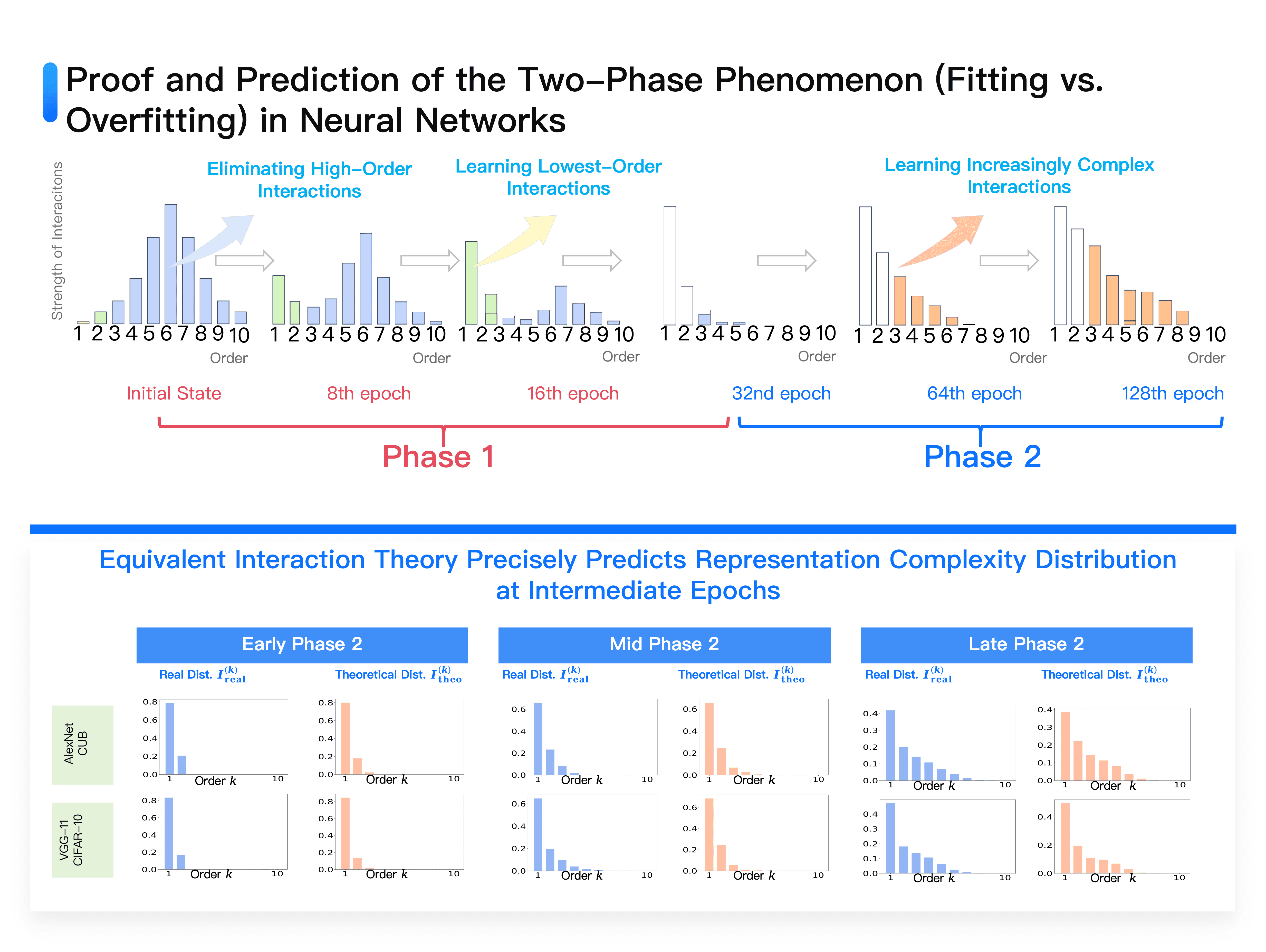
Diagram: Successfully proved and predicted the two-phase phenomenon of neural networks (fitting phase and overfitting phase): Neural networks eliminate high-order interactions in the first phase, ultimately only learning the lowest-order interactions; in the second phase, learn interactions of gradually increasing order.
We can theoretically prove that the training of any neural network can be divided into two phases.
The initial phase begins with the random initialization of neural network parameters. At this point, meaningful representations don't exist, all representations are like a tangle filled with noise, creating numerous complex interactions. Most of these interactions, however, are disordered. The learning process within neural networks sees intricate interactions adopting a spindle-like distribution: medium complexity interactions are most abundant, whereas very high and very low complexity interactions are relatively rare. Neural network learning falls into two phases:
⭐️ Phase one is the interaction noise reduction stage. The system methodically deletes non-generalizing noise interactions, focusing on learning the most reliable, simplistic interactions. During this stage, training losses and test losses predominantly align.
⭐️ Phase two is the complexity enhancement stage. Given the complexity of training data, solely relying on simple interactions cannot fulfill classification tasks, thus the system begins gradually elevating interaction complexity, transitioning from two-word to 3, 4-word combinations, increasingly enhancing complexity to handle more complicated data. During this stage, the discrepancy between training and test losses gradually widens. Although interaction counts increase, interaction quality and generalization diminish.
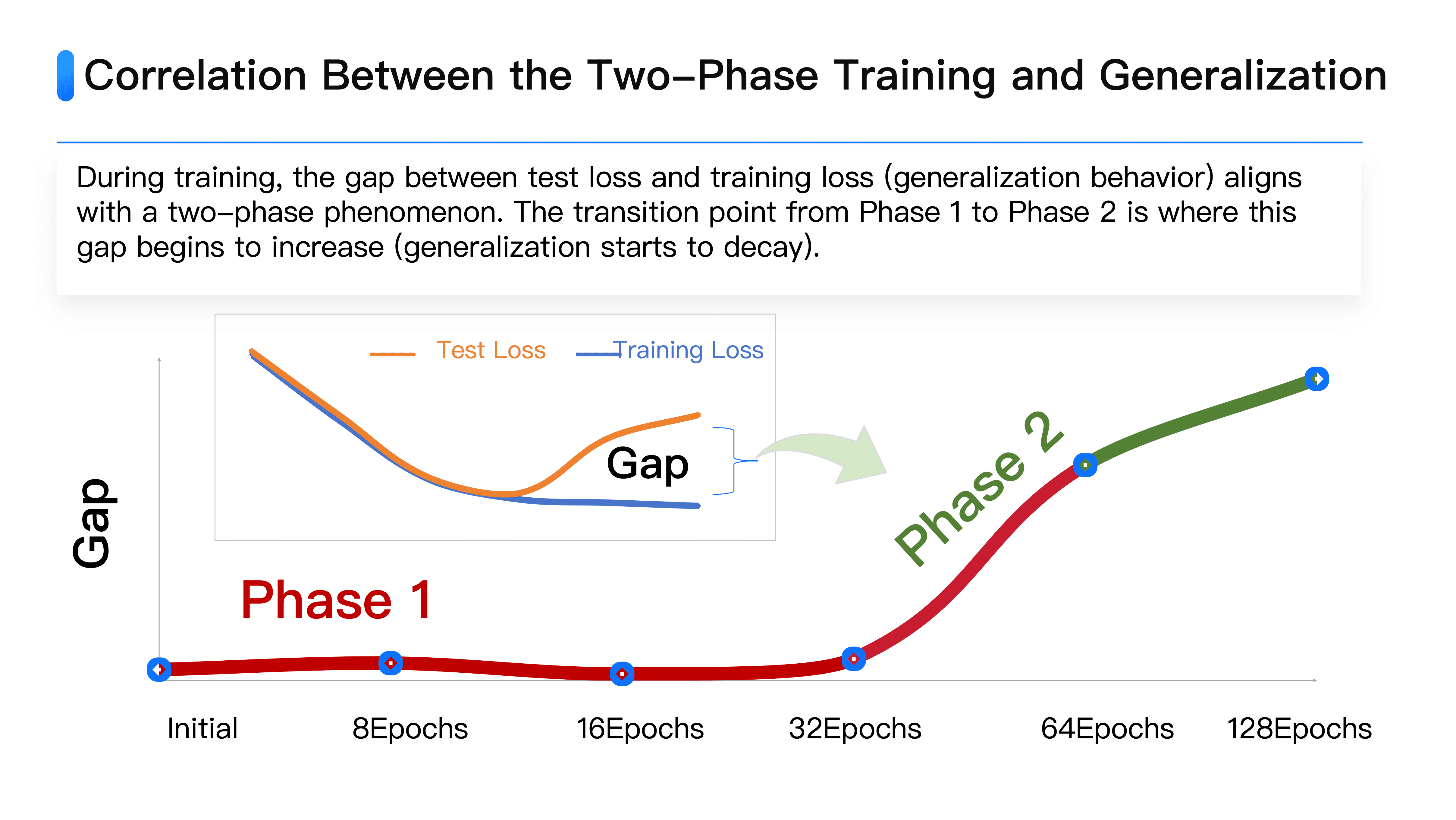
This two-phase phenomenon directly corresponds to neural networks' intrinsic learning reliability and generalization mechanisms. Traditionally, losses gauge generalization through loss functions: the larger the gap between test and training losses, the greater overfitting. We found the transition from phase one to phase two is precisely when training and test loss differences begin expanding from near-zero.
This mechanism is crucial for large model training. Using a dice analogy: Suppose six dice represent six different datasets or tasks. Traditional training resembles blindly shaking dice, ultimately yielding results with 4 dice landing on 6 and 2 on 1 and 2, signifying excellent performance on four tasks but poor on two. Further training is costly, and results aren't guaranteed, leaving no option but to accept the suboptimal result.
However, if real-time monitoring of large model two-phase phenomena across different datasets is possible, the scenario changes. Each dataset's fitting point varies: some datasets rapidly enter the second phase, others may stall in the first phase after 3-4 weeks of training, yet some may already overfit, requiring training cessation. This resembles conducting a CT scan of the training process, allowing observation of model dynamic changes on each dataset, identifying which data is overfit and which remains underfit.
Returning to the dice analogy, this method equates to dice transparency, immediately stopping to preserve when observing a rolled 6, resuming iterative rolls until all dice achieve 6, as opposed to blindly accepting the result of a single random roll.
We are currently engaging in industrial collaboration with several large model companies and developing a mature software system for dynamically tracking and comparing large model representation quality. Even if numerous interactions are shared between two large models, we can quantify distinct differences. For instance, some interactions are exclusive to Qianwen's large model and absent in DeepSeek or vice versa. Although most knowledge is common, these unique interaction modes distinctly reveal differences between models. This evaluation method resembles a CT scan, accurately pinpointing issues without directly treating diseases, which is paramount.
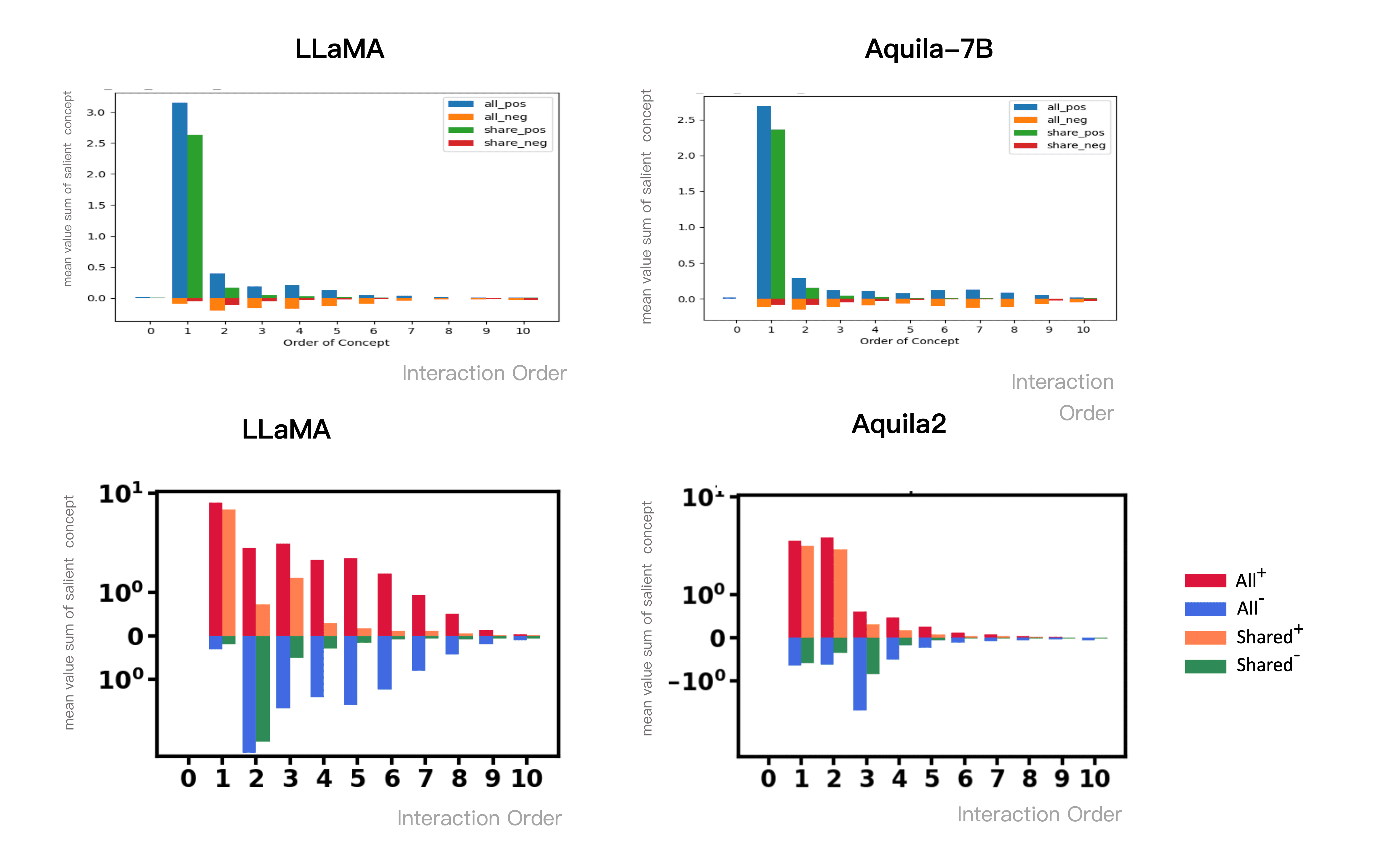
[Above Image] Compared to LLaMA-7B, the original Aquila-7B models more higher-order interactions and exhibits poorer representation quality: Both models share similar low-order interactions, yet Aquila-7B models a substantial number of high-order interactions unaffecting LLaMA-7B's higher-order interactions. [Below Image] Newly trained Aquila2-34B models a greater number of low-order interactions, delivering superior representation quality: Both models share similar low-order interactions, with LLaMA-7B incorporating a wealth of high-order interactions not modeled by Aquila2-34B.
We cannot persist with the "blind box opening" method, merely investing more capital and utilizing more graphics cards for training. The phrase "know the enemy and oneself, a hundred battles are never perilous" rings true. This system provides clear visibility of model changes on the same dataset over a day or a few hours of training: Is high-order complex interaction increasing or is first-order interaction increasing? Is the model in the first-phase denoising stage or the second-phase overfitting stage? These insights directly reflect model training quality and efficiency, enabling real-time tracking of large model generalization trends and training guidance.
Machine Heart: Has your software system been able to accurately observe these phenomena?
Quan Shi Zhang: Yes. Although we haven't tested it on large-scale models yet, we've clearly observed this phenomenon through various medium to small model tests. Additionally, it's supported by rigorous theory, with ample evidence proving the existence of these two-phase phenomena.
Some may worry that acquiring all outputs in different obscuration states poses a direct distillation risk. In actuality, we don't require many samples for evaluation. When the error rate hovers around 30%, a marginal difference between 30.5% and 30.3% isn't significant, needing only a few hundred samples for assessment. Theoretically, it's unlikely to complete knowledge distillation solely from these few hundred samples, thus ensuring safety.
More importantly, our software system is highly mature. If a customer's task or large model involves commercial secrets, the software can be directly deployed on the customer's local device to ensure data security.
Providing a Hard Indicator in Large Model Evaluation
Machine Heart: For commercial companies, especially leading large model companies, interpretability seems to have no direct linkage with performance. For instance, take the legal large model example you mentioned. If output results are correct but internal logic issues are detected by your software, companies may lack the motivation to disclose these results. Additionally, in less rigorous application scenarios such as novel writing, untethered imagination is often more valued. How do you view the value of interpretability in such contexts?
Quan Shi Zhang: From a broad commercial development perspective, there are serious issues in the current large model field. Although large models are recognized as a high-tech industry, they lack an authoritative hard indicator to strictly evaluate all large models in the field. Existing evaluation methods mainly rely on correctness testing (benchmark), value alignment assessments, and subjective user experience.
This evaluation system has evident drawbacks: leaderboard assessments can be "gamed" with targeted training; large model companies possess enough resources to gather data and boost leaderboard positions, compromising the reliability of assessments. Consequently, we find it challenging to accurately discern which large model is superior.
This situation does not bodes well for the industry:
💼 For large companies: Despite DeepSeek performing well, aside from recognition from a few leaders, there's no hard indicator demonstrating its superiority by generations. Various benchmarks could be conquered through targeted preparation, preventing companies from establishing robust technical barriers.
💼 For small companies: They might excel in specific fields (e.g., finance, law) over known large models, but unreliable traditional leaderboard systems cause users to still prefer known large models. This makes it difficult for small companies to gain recognition even when producing high-quality products.
We need to establish a new evaluation system from internal mechanism perspectives.
While examinations enable output answers to be correct through test preparation, remedying the logic chaos in internal representations, accountability reassignment issues proves daunting. This stable assessment system can:
👍🏻 Precisely highlight the gap with cutting-edge large models
👍🏻 Aid excellent small companies in standing out
👍🏻 Allow leading large models to solidify their competitive edge
Moreover, traditional evaluations mainly focus on error rates, but the real threat lies in seemingly correct cases with potential risks.
Take the legal field as an example, conspicuously wrong judgments are easy to identify (e.g., death penalty for theft), yet we need to examine judgments appearing correct but harboring potential ethical risks. Similarly, in autonomous driving's pedestrian detection, every near-accident needs examination and potential hazard identification.
Thirdly, from both government procurement and market access perspectives, once a model's internal mechanisms are explicable, public attitudes transform.
Collectively, humanity needs the right to be informed and, when issues arise, responsibility must be clearly assigned. Interpretability analysis permits identification of exact problem causes:
❌ If responsibility reassignment occurs, it indicates insufficient data cleaning.
❌ If expected learned interactions are absent, it implies insufficient data volume.
❌ If features are overly uniform, it signifies inadequate data diversity.
Future large model development requires new evaluation perspectives and hard indicators. Genuine performance improvement incurs significant costs, while merely pursuing superficial effects, like courting attention by cleverly quipping or amusing anecdotes, represents a perilous sign. What should AI companies aim for then? We need deeper evaluation of models' underlying mechanisms.
Interpretability Technology: Large Model Training's "CT Scan"
Machine Heart: From your perspective, this seems to deviate entirely from the traditional scaling approach. By 2025, everyone will focus on improving large model reasoning capabilities, whether by enhancing Chain-of-Thought or increasing computational power during reasoning. Does your analysis suggest all these training methods need to be completely rethought?
Quan Shi Zhang: Indeed, many current technologies are effective, and new theories cannot easily disrupt them. I believe interpretability technology should complement traditional technologies. Traditional empirical technologies hold the advantage of genuinely improving performance but lack controllability—they cannot assure improved performance like a stable equation, 1 + 1 = 2, across every task, model, and moment.
Interpretability technology aptly bridges this gap, adding model controllability. While we cannot predict definitively effective methods, we can clearly observe how representation changes in interaction quantity and complexity when employing Chain-of-Thought or introducing new data. This resembles a hospital's CT scan, though it cannot cure illnesses, accurate diagnosis and treatment are challenging without a CT scan.
Our goal is to evolve from the current end-to-end learning to interactive learning. Ideally, this learning approach emulates human interaction, enabling observation of issues through mid-level knowledge expression metrics, quantifying experiential algorithm efficacy. Essentially, building a relationship among empirical algorithms, knowledge representation, and performance is required, rather than simply assuming a method (e.g., adding Chain-of-Thought or cleaning data) will enhance performance.
Our direction is shifting black-box training to grey-box training, using continuous monitoring to determine when training should cease or overfitting begins—perhaps this marks future trending development.
Machine Heart: AlphaZero proved AI can surpass humans without human intervention. Will interacting learning, as you mentioned, limit AI's potential to exceed human capabilities?
Quan Shi Zhang: This feedback-based interactive learning differs from supervised learning. Supervised learning forcibly fits large models to mimic human thought, knowledge, and reasoning structures. Our approach is merely to eliminate evident errors. As for which interactions to learn, that's autonomously determined by large models—we are simply observers, not actively restricting its representation.
With such theoretical technology, discussions are not limited to whether large models excel or outperform humans—this binary quandary—but encompass the fundamental issues large models face at different stages and specific problems with the same dataset on varied large models, genuinely enhancing their learning.
Machine Heart: You've repeatedly mentioned long-chains, meticulous Chain-of-Thoughts. For mathematical and coding large models, their reasoning is naturally step-by-step verifiable. Some advocate using a model's CoT data to feed back into training. Is this approach feasible? What potential risks might exist?
Quan Shi Zhang: Using a large model to generate Chain-of-Thoughts back into training is excellent but, from a more rigorous standpoint, once data size reaches a certain magnitude, discussing data's simplicity, quality, diversity, etc., takes on a completely different dimension—there isn't a traditional notion of simple versus complex samples.
A neural network displays completely different behavior at different initializations: certain samples might produce generalizable interactions during the first training but, in a subsequent training, may spawn unconventional, high-order odd interactions. This illustrates that samples' quality, generalization, and reliability aren't inherent attributes but must be jointly considered with the neural network's fit-degree.
We need to yield discourse to the neural network, letting it indicate which samples are reliable and which are not. Interpretability technology undertakes this task without simply examining datasets. Empirical technology efficacy requires a stringent algorithmic system for evaluation and assessment rather than a blind assumption that adding Chain-of-Thought or more data invariably boosts performance.
Ten Years Honing a Sword: How to Identify "Big Problems" in AI Research
Machine Heart: What advice would you give young scholars eager to delve into AI interpretability research?
Quan Shi Zhang: I turned to interpretability research in 2015, a time without large models. Although deep learning thrived and neural networks exhibited entirely different intelligence forms, with soaring performance, I noticed a potential issue: The manipulable dimensions for humans were decreasing, and the grip over knowledge was waning.
In the traditional neural network era, primarily two things could be done: adjusting network structures and loss functions. Entering the large model era, due to enormous training costs, even these became inaccessible for most researchers. Now, researchers focus on collecting, cleaning data, and prompt engineering. Despite the explosive growth of AI researchers, they're wedged into a shrinking research space, reducing developmental dimensions steadily.
Choosing interpretability research stems from its nature as a top-down system, supplementing neural networks. Research can be classified into two types: engineering research, focusing on excelling at problems and optimizing performance; and theoretical research, prioritizing problem selection over performance enhancement.
Regarding theoretical research, how should one choose a worthwhile problem? I set three standards for myself:
✅ Identify common issues. Not superficial problems (e.g., high training costs, insufficient accuracy) but intersection points encapsulating the fundamental reasons for most field problems. Finding such an issue is a daunting task in itself, but once identified, one's work cannot be ignored.
✅ This problem must be mathematically modelable, have clear boundaries, and be provable or refutable. Reviewing neural network history: initially, ResNet was regarded as the strongest, now it's Transformer, with potential new structures emerging. In the generation network spectrum, it transitioned from VAE to GAN, now to diffusion models. Following trends appears safer, yet fundamentally, it's akin to gambling—when an issue lacks rigorous proof or falsification mechanisms, risks amplify.
✅ Pursue lesser-traveled roads. Success isn't about competing in intelligence or investment but finding paths untreaded. Like interpretability research, I must explain knowledge representation, generalization, robustness, etc.; while much work remains untold here, this forms a lengthy roadmap necessitating strategic planning to establish influence.
In my view, "ten years honing a sword" involves spending a decade identifying a problem worth investing in simultaneously meeting these three conditions, then committing another 10 or even 20 years proving conclusions to resolve it.
Machine Heart: If you wait ten years without finding such a problem, or realize there's been a mistake, what then? Suppose the interaction theory explaining neural network internal representation is ultimately proven wrong, what would you do?
Quan Shi Zhang: That's a great question, something many students also inquire about. The world's directions are never 100% right or wrong. The three criteria I mentioned earlier ensure one's efforts aren't wasted.
In 2017, I first wrote on Zhihu, discussing the future of interpretability and deep learning. I realized this issue was widely acknowledged as important yet almost unattainable to tackle. Despite countless related papers, few truly address it from a perspective of theoretical rigor.
During that period, I was constantly exploring, swept along by the era's tremendous tide, easily at risk of losing direction. Research isn't just a one or two-year endeavor; to travel far in academia, one may need 10 or 20 years, but finding an opportunity to define a problem is key. Though difficult, finding a fundamental problem possible to model mathematically and explore new pathways is essential for genuine domain advancement.


