

1. Background
There has long been a misconception about large models, assuming they can only be assessed indirectly through external tests as a black box, making it difficult to directly grasp the representational quality of large models and the correctness of the knowledge and logic they model.
However, our newly proposed technology has successfully broken this dilemma.
Research has shown that when a large model generates a sentence, the confidence score of producing a token can be interpreted in the form of "AND-OR" interaction logic. Specifically, for a given input sentence, we have demonstrated that large models are capable of modeling only a limited number (around 100) of interaction relationships between input words. Each interaction relationship corresponds to an AND-OR logic operation and contributes a certain score. It can be proven that the overall output confidence of the neural network can be precisely fitted using these interaction scores. Given an input sentence, we can exhaustively enumerate all possible masking states of the input units. No matter how we mask the input units, it can be proven that this AND-OR interaction logic model can still precisely fit the variety of outputs from the neural network under exponential masking changes.
This discovery provides a fundamental theoretical guarantee for understanding the decision-making mechanism of large language models—it ensures that the symbolic logic used to explain neural networks is no longer stuck at the engineering fitting stage but theoretically guarantees the rigor of the explanatory values.
2. Scientifically Evaluating Generalization Ability of Large Models
From this new perspective, we can evaluate the generalization ability of large models directly from the level of detailed interaction logic they model. Since the output confidence of a neural network can be represented as the sum of the numerical utility of different interaction logics between input words, we can directly quantify the generalization form of different interaction logics to infer the overall generalization of the large model. Generalizable interaction logics specifically refer to those that can activate through transfer to test samples and assist the model in classifying the samples.
More importantly, by observing the generalizable and non-generalizable interaction logics within a neural network, we discovered and partially proved that generalizable and non-generalizable interaction logics often follow different distributions in terms of interaction order. The order of interaction refers to the number of input words involved in the interaction, i.e., the complexity of the interaction. Generalizable interactions typically exhibit a "decay" distribution characteristic: most generalizable interactions belong to simple, low-order interaction logic, while the numerical utility of slightly higher complexity interaction logic declines exponentially as complexity increases. In contrast, non-generalizable interactions exhibit a "spindle-shaped" distribution characteristic, where interactions of medium complexity dominate, but their numerical utility cancels out positively and negatively. It is particularly noteworthy that neural networks rarely model extremely simple and extremely complex non-generalizable interactions.
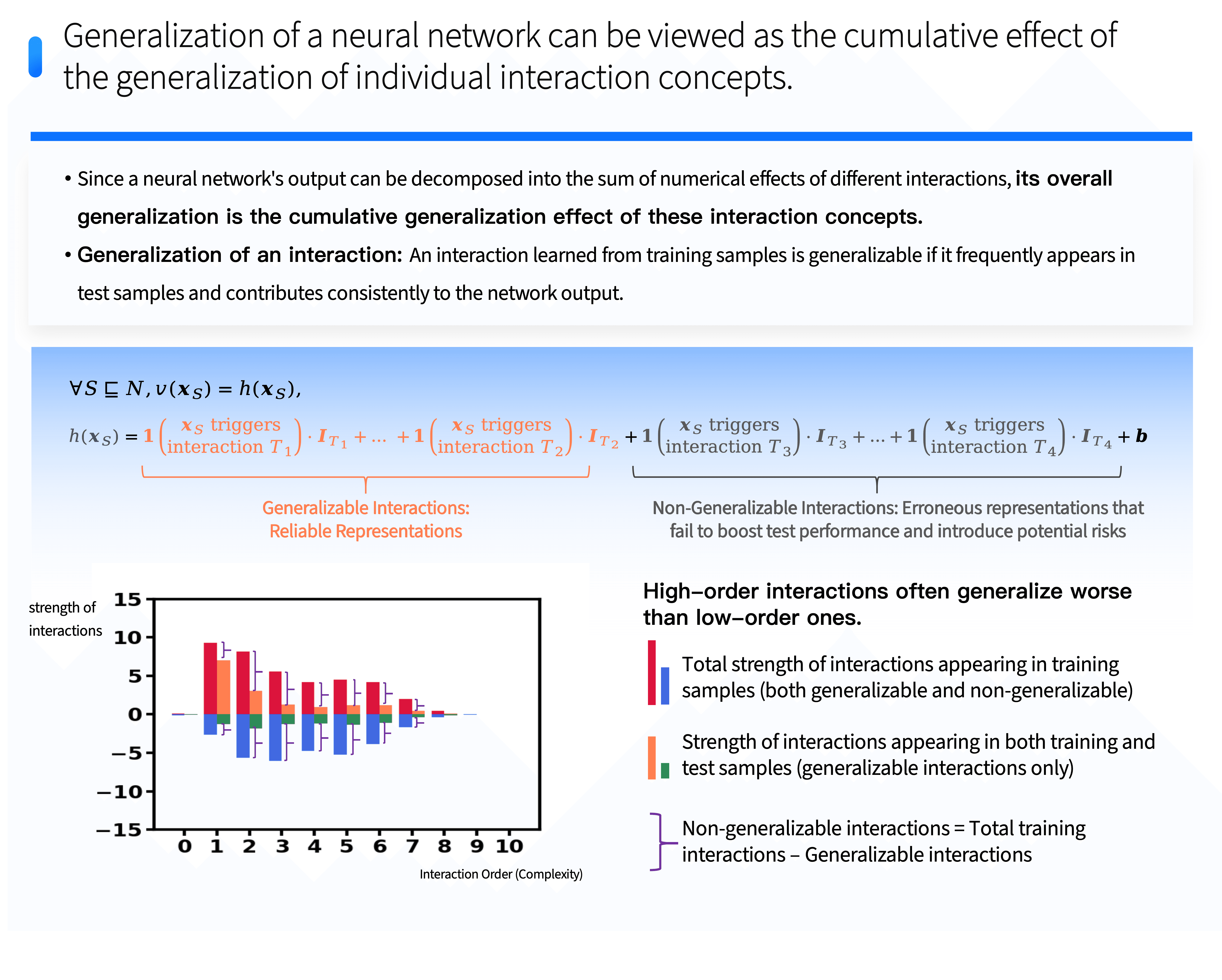
This technology completely bypasses the traditional framework of end-to-end black-box testing, as it shows that we can directly judge its generalization ability by analyzing the distribution of interaction complexity on a single sample of a neural network, without needing to evaluate network performance using a large test set as traditional methods do. This represents a major advancement—we can assess and understand the generalization characteristics of neural networks more efficiently.
3. Comparing Two Mainstream Large Models
Here, we compare two mainstream large models: DeepSeek and Qwen. deepseek-r1-distill-llama-8b is a model with 8 billion parameters, while Qwen's qwen2.5-7b has 7 billion parameters, with a similar amount of parameters.
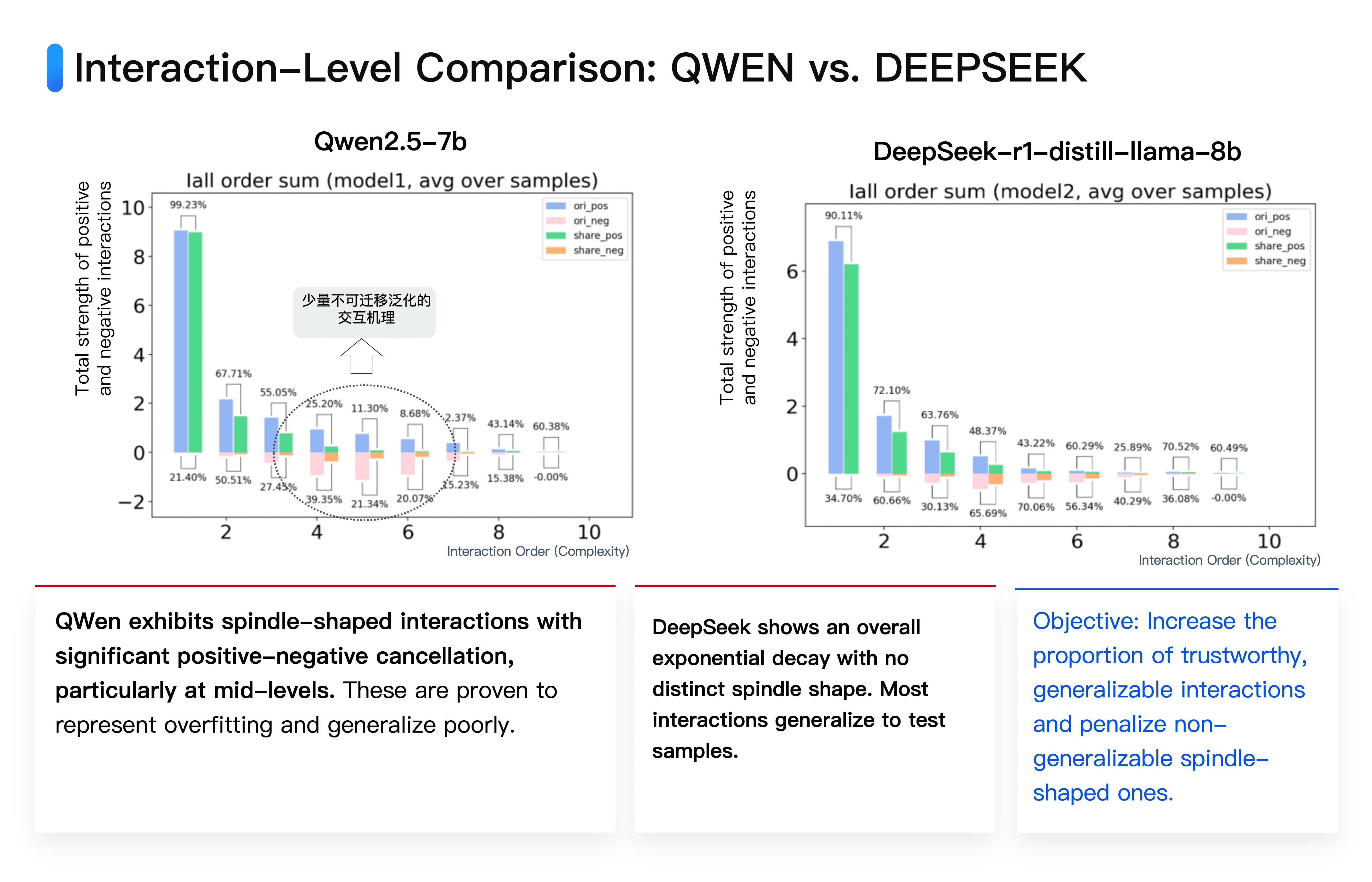
Our tests show that when given the same input, the interaction logic modeled by the two models has a high degree of similarity. It is specifically manifested in two major characteristics:
⭐️ First, most of the interaction logic produced by the two models for the same input overlaps. In other words, a significant amount of notable interaction logic modeled by DeepSeek is often also modeled by Qwen; the reverse also holds true.
⭐️ Second, our algorithm reveals from the perspective of interaction complexity distribution the potential shortcomings of the Qwen 7b model compared to the DeepSeek 8b model.
The Qwen 7b model models additional "spindle-shaped" non-generalizable interaction logic, i.e., interactions of medium complexity that numerically cancel each other out, which is theoretically proven to often indicate overfitted noise. In contrast, most interactions modeled by DeepSeek are typically generalizable, and the positive and negative cancellation effects between interactions are much smaller.
Based on this finding, we have developed a new method to evaluate the performance of large models. Whereas large datasets were previously necessary for testing, now performance judgement can be made by analyzing the internal interaction complexity distribution with only a few samples. This assessment dimension can scientifically reflect the true level of the model.
There are many reasons for these non-generalizable interactions, and of course, each cause can be precisely analyzed and traced mathematically. Some require extending the training time on specific datasets, some require shortening the training time while increasing the primary nature of samples, and some require data clarity, all of which can be analyzed from a mechanistic level, and will not be elaborated here.


