

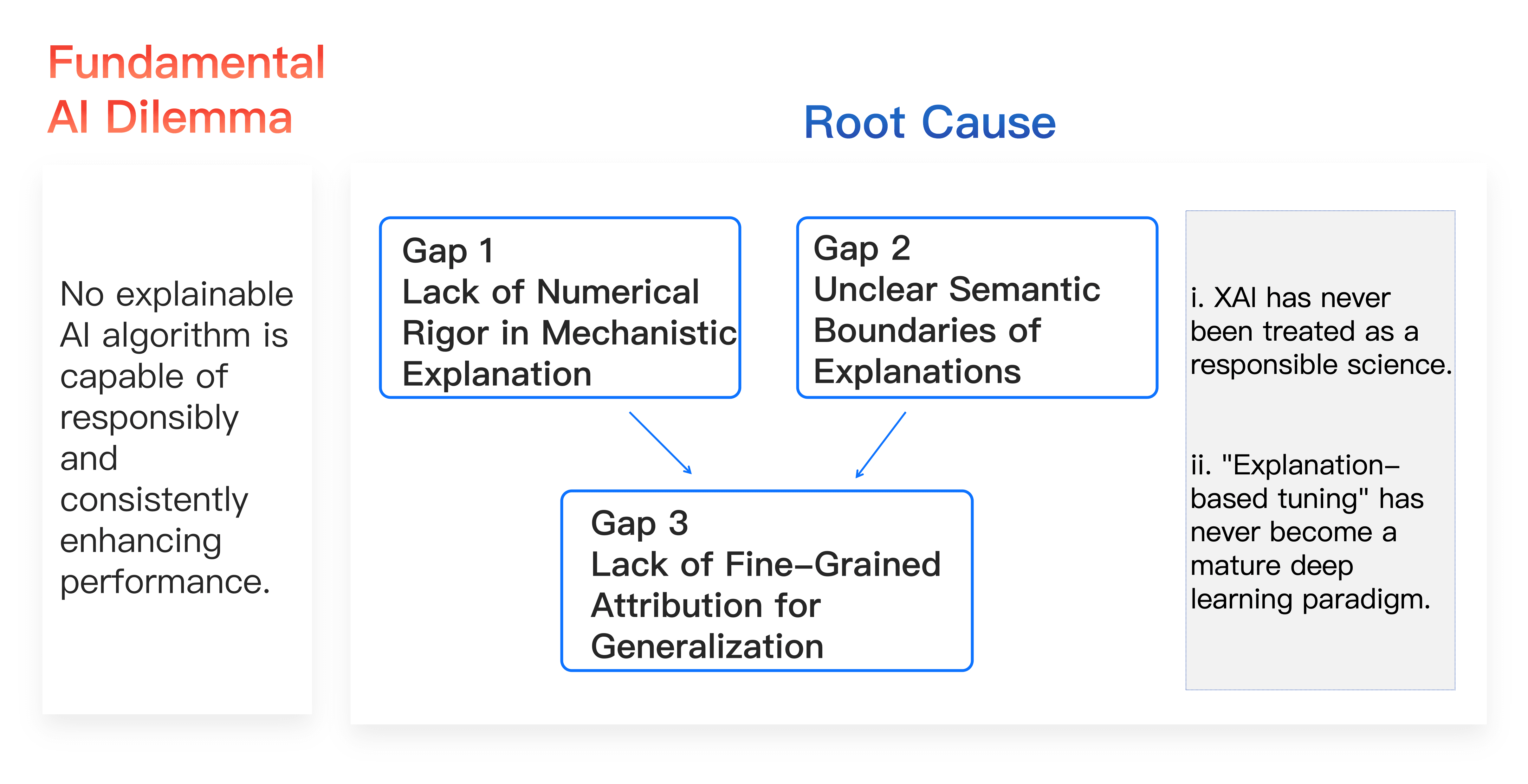
1. The Fundamental Dilemma of AI
Since the breakthrough in deep learning in 2012, for the past 13 years, very few papers have clearly defined the interpretability problem. Consequently, "interpretability research has not systematically and consistently improved neural network performance" (this is an external manifestation). The core scientific problem is that "a large number of interpretability issues have never been defined within a rigorously expressible mathematical category." Whether internationally or domestically, the vast majority of interpretability project plans and research conclusions lack "proof," "refutability," and even the certainty of their "mathematical boundaries."
❓ Do large models take shortcuts during reasoning?
❓ Is poetry generated by large language models spontaneous or planned?
❓ Do large language models have their own native languages?
Research remains stagnant when delving into the inner representation mechanisms of neural networks—
❌ Unable to provide absolutely clear conclusions
❌ Empirical rules cannot stably serve as a solid foundation for future research
❌ Consequently, cannot fundamentally enhance the performance of neural networks.
Interpretability research fundamentally belongs to "scientific exploration from 0 to 1," whereas academia often prefers pursuing "technical advancements from 10 to 100."
Therefore, we need to reorganize and define core issues from "representation mechanisms" to "model performance" within the interpretability domain. By reformulating various external issues (e.g., empirical conclusions on generalization, reasoning chains, and logical inference) into a clearer theoretical framework, we can present an interpretability framework with "clear mathematical boundaries," "rigorously verifiable strictness," and "precise explanations of neural network representations." However, why is this important? People often philosophically suggest "bypassing the constraints of Scaling Laws to precisely debug neural networks through explanation results," but this is not a problem that simple engineering algorithms can solve. The internal complex logic of neural networks is far more intricate than most interpretability algorithms. If the interpretation of neural networks cannot match the complexity of their internal representations, vague explanations will struggle to truly guide enhancements in neural network performance.
2. Three Critical Issues
In various international and domestic interpretability project plans, the following three critical issues remain overlooked:
Gap 1: Lack of numerical rigor in mechanistic explanations.
Current interpretability research rushes to showcase explanation results while neglecting the core question—whether the explanation results rigorously reflect all details of the neural network's representation mechanisms. "What constitutes an effective explanation" is not subjective conjecture but requires validation of rigor through numerous stringent conditions. For instance, lacking theoretical tools to prove that explanation results can cover a neural network's entire decision logic over a sufficiently large sample set (such as 2n test samples), ensuring that sparse interaction logic can accurately fit all output values of neural networks under exponentially changing input samples.
Gap 2: Unclear semantic boundaries of explanation results, thus not serving as strict diagnostic evidence.
Existing explanation methods (such as sparse autoencoders (SAE) and attribution graphs widely used by Google and OpenAI) extract semantic concepts relying on approximate estimations, lacking clear semantic boundaries and falsifiability. In judicial judgments or model evaluations, explanations lacking semantic rigor cannot serve as reliable evidence for identifying model representation flaws.
Gap 3: Lack of fine-grained attribution mechanisms for generalization capabilities (based on Gap 1 and Gap 2).
Current methods fail to establish a strict derivation path from explanation results to model generalization performance. Efforts should be made to attribute confidence changes in neural networks across exponential sample sizes to contributions of different interaction logics, thereby numerically establishing a derivable relationship between "representation quality of interaction logics" and "model performance," surpassing vague qualitative assessments based solely on statistical accuracy.
To date, solutions to any of these issues remain nearly nonexistent outside project teams, with no research conclusions based on experience offering a solid and reliable foundation for subsequent work. Our "interpretability theory system based on equivalent interaction" comprehensively breaks the inertia that "the complex representation logic of neural networks cannot be rigorously and thoroughly explained" from the fundamental theory level, restraining the application development in the entire interpretability domain. By approaching it from the angles of "explaining model decision mechanisms," "explaining model performance," and "unifying empirical algorithms," we incorporate numerous interpretability issues, which were previously difficult to define numerically, into the category of "parsable representations" and "rigorously provable and verifiable" frameworks.
Research Background
The symbolic evaluation and optimization of neural networks' detailed decision mechanisms is the core problem within the neural network interpretability domain and has been a long-standing technical bottleneck. The academic community still lacks formal theoretical modeling for this issue, and many scholars have published opinion articles calling it an "impossible problem to solve."
⭐️ Bottleneck 1: Both intuitively and experimentally, it has been long believed that it's impossible to use a set of 'sufficiently simple symbolic expressions' to explain the 'extremely complex representation logic' within neural networks. Consequently, traditional interpretability techniques have consistently failed to break through the strict explanation of neural network decision logic.
⭐️ Bottleneck 2: The incapacity of traditional theories to explain root causes of large model performance. As traditional generalization analysis methods based on feature space gradually decline in the era of large models, explaining the fundamental reasons that determine large model performance (generalization, robustness) is impossible. Essentially, the unavoidable developmental barrier in the interpretability domain can be distilled into a fundamental scientific question: Is it possible to rigorously and comprehensively explain the representation logic and performance of neural networks through concise symbolic logic? More precisely, under what conditions can symbolic logic concepts rigorously explain the various detailed decision mechanisms modeled by neural networks and overall model performance? Beyond the applicant team, no serious theoretical modeling has been undertaken internationally to address this question.


